Detect code plagiarism with evidence you can trust
A source code plagiarism checker that finds logical and structural similarity across peer submissions and the public web. Weighted detection, side‑by‑side diffs, and explainable reports reduce false positives.






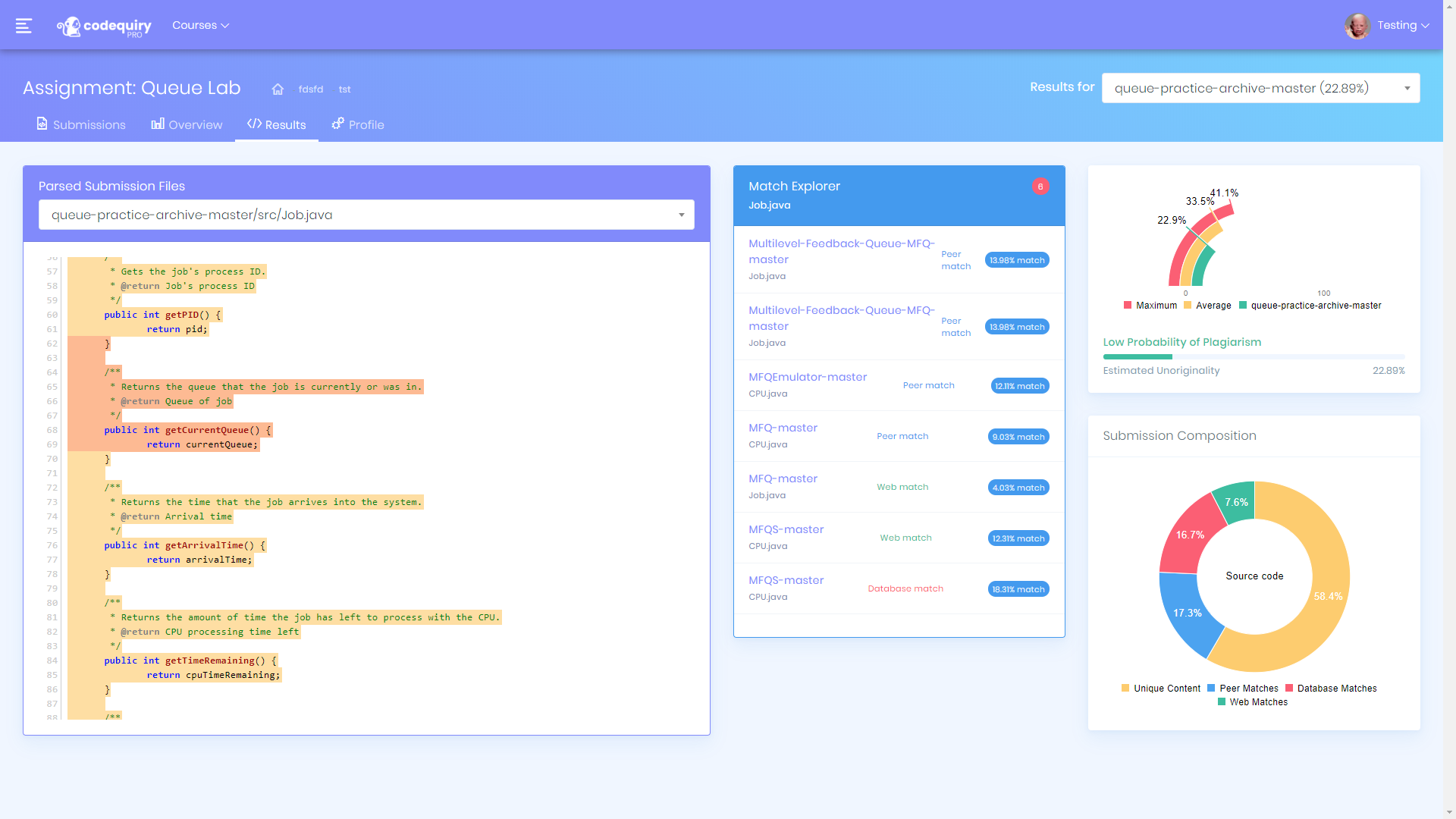
Find unoriginal code with precision
Highlight logical and structural similarities across student submissions and billions of web sources. Reduce investigation time with clear, verifiable evidence and visual maps of suspected collaboration.
Why choose Codequiry, the code plagiarism checker educators prefer
A modern code plagiarism checker and code plagiarism scanner designed to minimize false positives and surface real plagiarism.
Peer similarity detection
Token-based and structural analysis finds clusters of similar submissions, even when variables and formatting change.
Web source matching
Checks billions of sources and popular blocked sites to catch copies from GitHub, Stack Overflow, CourseHero, and more.
Weighted detection
Down-weights cosmetic changes and prioritizes logical similarity to reduce false positives.
Visual node map
Interactive graphs help you quickly spot collaboration clusters and outliers.
Broad language support
Works across common languages and frameworks used in coursework and technical interviews.
API and CLI
Automate checks in CI/CD or LMS workflows via REST API and command-line tools.
AI‑written code indicators
Spot generated-code patterns and mixed‑authorship risk with explainable signals.
Explainable reports
Side‑by‑side diffs, source links, and similarity clusters organized for quick review.
Built for real workflows
From computer science courses to coding competitions and hiring assignments
Universities & colleges
Check entire cohorts for collaboration and reuse, review evidence in minutes, and export reports for committees.
Coding competitions
Detect shared logic and template reuse during or after events with clear, defensible findings.
Hiring & take‑home tests
Verify originality of candidate submissions and flag obvious copies from public repositories.
Code plagiarism checker vs alternatives
What you get compared to classic tools
| Capability | Codequiry | MOSS/JPlag | Generic text tools |
|---|---|---|---|
| Web & GitHub scanning | Yes | Limited/No | No |
| Structural analysis | Advanced | Basic | No |
| Weighted false‑positive control | Yes | Partial | No |
| Explainable reports | Diffs, links, clusters | Basic | No |
| API & CLI | Yes | Limited | No |
What is a code plagiarism checker?
A code plagiarism checker (also called a code plagiarism scanner) analyzes source code to find logical and structural similarity between submissions. Unlike text plagiarism tools, it focuses on tokens, control flow, and program structure, so it can detect copying even if variable names, comments, and formatting are changed.
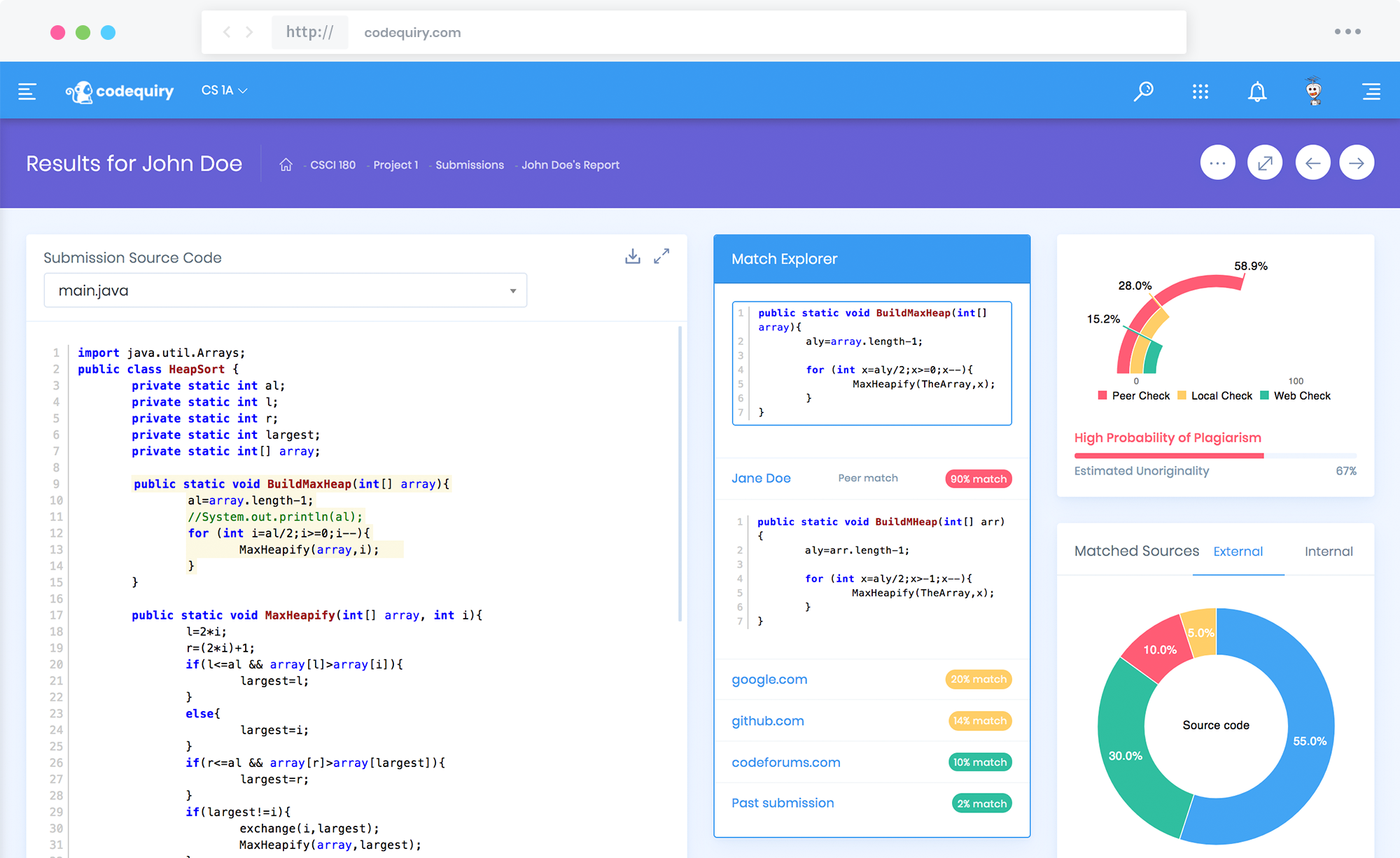
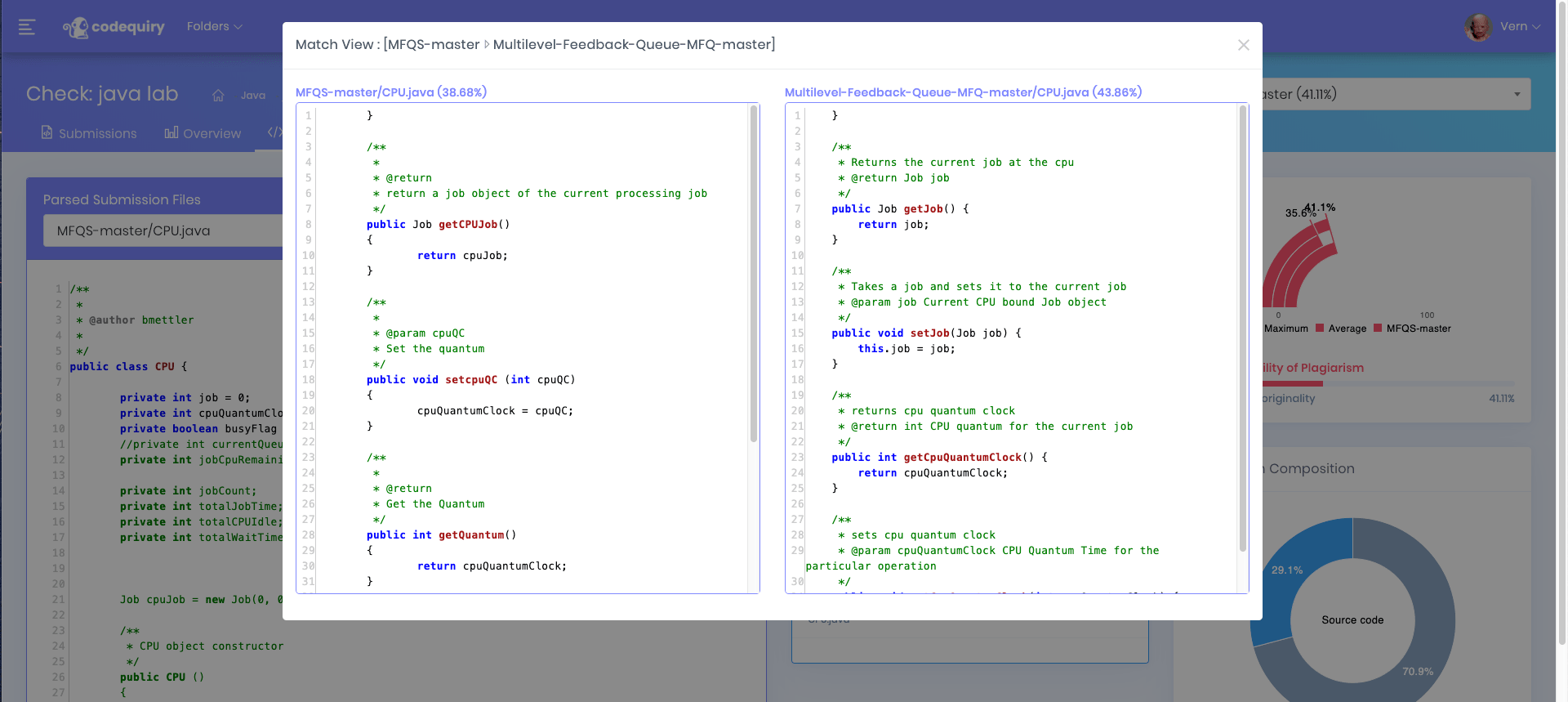
Codequiry compares peer submissions and public web sources to surface likely matches with evidence such as side‑by‑side diffs, similarity scores, and collaboration node maps.
Related pages
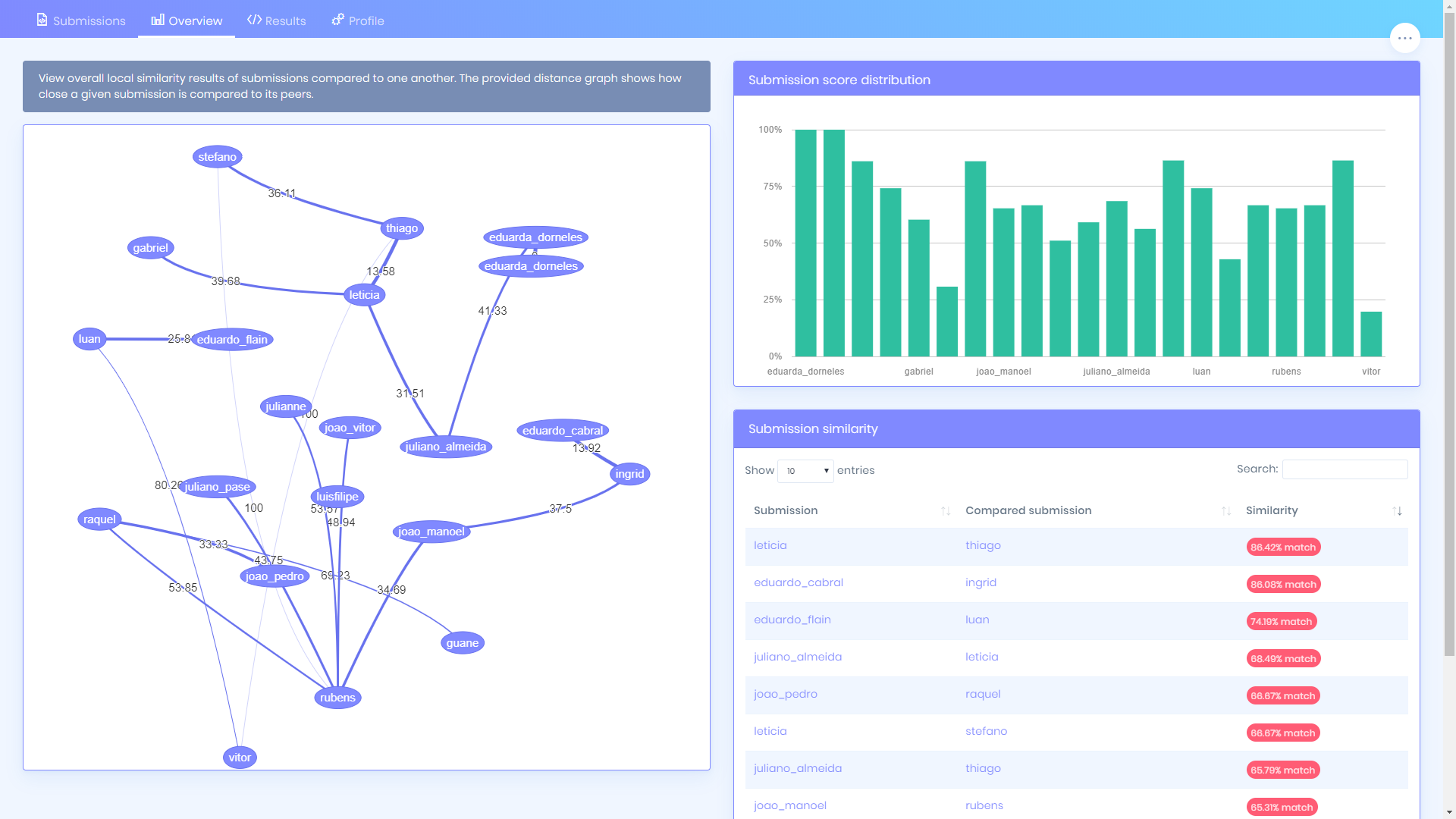
How the checker works
Tokenize and normalize code
Removes punctuation/whitespace and normalizes identifiers to focus on structure and logic.
Compare at scale
Performs peer-to-peer and web comparisons using statistical techniques for speed and accuracy.
Surface actionable evidence
Generates similarity scores, side-by-side diffs, and node maps for fast investigation.
Screenshots
A quick look at the code plagiarism checker in action
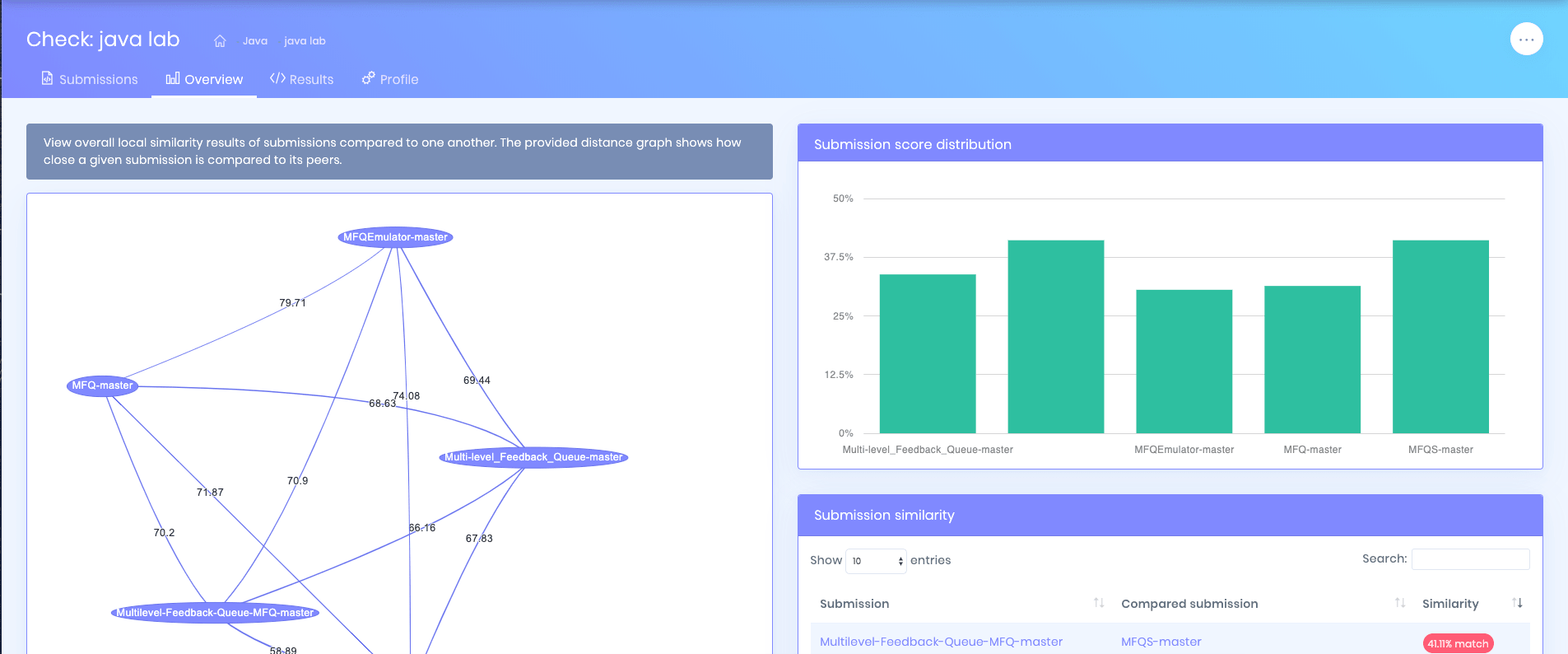
The complete guide to code plagiarism detection
Everything educators and teams need to know about detecting code plagiarism, improving accuracy, and running fair investigations
What is code plagiarism?
Code plagiarism is the presentation of someone else’s source code as one’s own without proper acknowledgment. Unlike text plagiarism, which typically matches words and phrases, code plagiarism involves logical and structural similarity. Students or candidates can attempt to disguise copying by renaming identifiers, changing whitespace, reordering blocks, or inserting dead code. Effective detection therefore requires analyzing program structure rather than surface-level tokens alone.
In academic settings, code plagiarism undermines learning outcomes, grading fairness, and accreditation standards. In industry, it damages trust and creates legal and compliance risks when copied snippets carry incompatible licenses. A modern code plagiarism checker must balance sensitivity and specificity, surfacing true matches while minimizing false positives, so instructors and reviewers can act with confidence.
How code plagiarism detection works
Codequiry combines multiple layers of analysis to detect similarity beyond superficial changes. The process begins with normalization (removing non-semantic punctuation and whitespace) and tokenization (splitting code into syntactic units). Next, we extract higher-order structure, including abstract syntax trees (AST), control-flow graphs (CFG), and data-flow relationships, so that logically equivalent programs remain comparable even after renaming or minor refactors.
- Token signals: n‑grams and shingles highlight repeated fragments across submissions, useful for exact and near‑exact matches.
- AST structure: tree shapes, subtrees, and operator patterns identify algorithmic similarity and canonical solutions.
- Control flow: loops, branches, and call structure reveal deeper similarity across reordered blocks.
- Identifier heuristics: robust handling of renaming, casing, and comment manipulation reduces noise.
At scale, we perform peer comparisons inside a cohort and web scanning across public sources like GitHub and Q&A forums. Matches are corroborated with evidence: side‑by‑side diffs, highlighted regions, and links to sources. A weighted detection model prioritizes structural similarity over cosmetic changes, helping to suppress false positives.
Common evasion tactics and how we catch them
- Renaming variables and functions: Structural analysis largely ignores symbol names and focuses on usage and relationships.
- Reformatting and whitespace edits: Normalization removes formatting artifacts before matching.
- Reordering code blocks: CFG‑aware comparisons preserve logical execution order even if files are rearranged.
- Dead‑code insertion: Entropy checks and path analysis de‑weight unexecuted fragments.
- Template reuse: Cluster analysis flags cohorts sharing the same skeleton or uncommon scaffolding.
- Copying from the web: Web‑source matching links local code to public repositories and posts with precise line‑level evidence.
Accuracy, precision, and false positives
Any detection system must balance recall (catching as many true cases as possible) with precision (avoiding false flags). Codequiry’s weighted approach reduces over-sensitivity to trivial edits and prioritizes signals that correlate with copying. Instructors can tune thresholds to align with course policy, and results include explainable evidence such as diffs, matching regions, source URLs, and cohort maps, so that decisions are transparent and defensible.
Instructor workflow
- Collect submissions: Drop a folder or zip; our system auto‑detects languages and projects.
- Configure checks: Enable peer comparison, web check, and optional AI‑written indicators.
- Run checks: Process entire cohorts in parallel with rate‑limited web requests.
- Review evidence: Open reports with similarity scores, diffs, and links to corroborating sources.
- Take action: Export summaries, attach evidence to case files, and document outcomes in line with policy.
Best practices for fair investigations
- Use consistent thresholds across a class to avoid bias.
- Corroborate high scores with qualitative review of diffs and source links.
- Consider assignment design that discourages copying (unique inputs, randomized specifications, oral checks).
- Communicate expectations in the syllabus and state that all code is checked for originality.
- Maintain records of evidence and outcomes to ensure due process and transparency.
Comparing code plagiarism tools
Classic tools like MOSS and JPlag pioneered similarity detection but often lack modern web scanning and robust structural weighting. Generic text‑plagiarism products underperform on code because they treat source files like prose. Codequiry specializes in program analysis, pairs peer and web checks, and produces reports designed for academic committees and engineering managers.
APIs, CLI, and bulk import capabilities
Beyond the web app, you can automate checks via REST API and our desktop/CLI tools. Instructors can bulk import from LMS workflows, and engineering teams run checks in CI/CD for coding challenges and take‑home tests. See the documentation for endpoints, SDKs, and recommended patterns for batching, retries, and artifact management.
Ethical use and privacy
Institutions should apply code plagiarism detection to uphold fairness, not to punish inadvertently. Provide students with clear policies, avenues to discuss results, and opportunities to learn from mistakes. Codequiry follows security best practices and aims to minimize collection of personal data beyond what is necessary for analysis and reporting.
Key takeaways
- Structural analysis is essential to detect disguised copying.
- Web‑source matching connects local similarity to public origins.
- Weighted detection helps avoid false positives and focuses on meaningful overlap.
- Explainable evidence supports fair, defensible outcomes.
Glossary
- AST: Abstract Syntax Tree representing code structure.
- CFG: Control‑Flow Graph representing execution paths.
- Normalization: Removing non‑semantic differences such as whitespace.
- Shingling: Breaking content into overlapping n‑grams for matching.
Further reading
Evidence that reduces guesswork
- Similarity clusters and node map
- Side-by-side highlighted diffs
- Peer and web-source breakdown
- Weighted scoring to avoid false flags
Built for academic integrity
Preserve fairness in your courses by consistently evaluating originality across all submissions. Confirmed cases help the model continuously improve detection strategies as behaviors evolve.
Frequently asked questions
Quick answers about detection accuracy, sources, workflow, and how our code plagiarism checker and code plagiarism scanner work.
How does Codequiry minimize false positives?
By weighting structural and logical similarity over superficial elements like variable names or comments, then corroborating with peer and web matches.
What web sources are checked by the code plagiarism checker?
Billions of sources including popular repositories and blocked content platforms used by students.
Can I automate code plagiarism checks?
Yes. Use the REST API and CLI to integrate Codequiry into CI/CD pipelines, LMS, or custom scripts.
What happens after a case is confirmed?
Confirmed cases help improve the system by reinforcing features that correlate with true plagiarism.
Does it catch renamed and reformatted code?
Yes. Structural analysis and control‑flow patterns reveal similarity beyond variable names and whitespace.
Is there a desktop/CLI option?
Use the desktop client to run checks locally and script uploads.
Ready to protect academic integrity?
Get started and run your first check in minutes.
Get Started Free